Numerology
From Where Comes Numerology?
We start with a short description of from where numerology comes and what numerology is.
Numerology is an arcane system of beliefs about numbers which comes to us out of the depths of time. According to my main reference for numerology, Numerology Has Your Number, by Ellin Dodge, published by Simon and Schuster, in 1988, early humans found numbers to be magical and early civilizations gave special significance to numbers. The numerology that we use today is ascribed to the Ancient Greek mathematician, Pythagoras. (Pythagoras is the same Pythagoras known for the Pythagorean theorem in mathematics.) Ms. Dodge writes that, as far as we know, the system was passed down by his disciples. Historians do not think Pythagoras wrote down his numerological system.
Numerological Basics
The basic numbers used in numerology are the digits one through nine. According to numerology, each of the digits has a variety of meanings (e.g., one meaning associated with the number two is cooperation). Since most numbers contain more than one digit, numerologists must reduce numbers to one digit for interpretation. Any number that does not contain indefinitely many digits may be reduced to a single digit by repeatedly adding the digits in the number. For example, 2429 sums to 17 ( 2 plus 4 plus 2 plus 9 ), which sums to 8 ( 1 plus 7 ), so the numerological number associated with 2429 is eight.
In mathematics, when one divides any positive integer by any other positive integer, the remainder is called the original integer ‘modulo’ (or ‘mod’) the other integer. Finding the value of any positive integer modulo nine gives the same result as repeatedly adding the digits in the integer, provided zero is set to nine in the final result. To continue on with the example given in the last paragraph, 2429 divided by 9 equals 269 with a remainder of 8. We can see that the remainder is the same as the number found by repeatedly adding the digits in the number. For another example, 207 divided by 9 equals 23 with a remainder of 0, which we set equal to nine. Using the numerological method, 2 plus 0 plus 7 equals 9.
Dates can be reduced to a digit by adding the sum of the digits in the month’s number (e.g., 8 for August or 1 plus 1 for November) to the sum of the digits in the day of the month (e.g., 2 plus 8 for the 28th) to the sum of the digits in the year (e.g., 2 plus 0 plus 0 plus 9 for 2009). Today is October 1, 2009, so the numerological number associated with this day is 4 (1 plus 0 plus 1 plus 2 plus 0 plus 0 plus 9 and 1 plus 3).

Birth Dates
Birth dates have a special meaning in numerology. Ms. Dodge calls the numerological number associated with a person’s birth date the destiny number. According to Ms. Dodge, destiny numbers represent where we are going in life, what we have to learn. For example, persons with the number two destiny are learning cooperation and the art of making peace. I think of number two people as deal makers, coordinators of people. On the other hand, persons with the number eight destiny are learning about material success and the management of resources and people. The number eight is associated with material ambition.
Birth Dates of the Presidents
I tend to calculate the numerological number of dates when I see them, so, when I was looking through a pamphlet about the U.S. presidents, just out of curiosity I calculated all of the presidents’ destiny numbers. I noticed that the earlier presidents seemed to have smaller destiny numbers than the later presidents, particularly if one ignores the two’s and the eight’s. To the left of this page is a list of the presidents along with the presidents’ birth dates. Also, I have included a plot of the presidents’ destiny numbers below. The pamphlet was one that my family picked up when I was young and did not have the more recent presidents, so Reagan’s, Clinton’s and Obama’s two’s were not in the pamphlet.

Statistics
Where to Start?
Being a statistician, I began to think about how one could test if there is reason to think that the later presidents were chosen by the people because they had higher destiny numbers or if the apparent trend could be explained by chance. When working with birth data, one needs to be aware of the underlying distribution of the variable of interest (in this case, the destiny number) in the population of interest (in this case, let us say, the population of all of the native male citizens from the country’s inception). Birth information about the population of all of the native male citizens from the country’s inception does not exist, though we might be able to estimate the distribution of destiny numbers from historical documents. I will be lazy and just assume that, throughout the history of our country, native male citizens were born evenly under each of the nine destiny numbers. The pattern of destiny numbers repeats every 36 years and over a 36 year period, every destiny number comes up 1461 times.
I decided to break the data at Lincoln, not because there seemed to be a shift with Lincoln, but because I suspect the country matured with the experience of the Civil War. (Note, I am not a historian or student of history.) Having decided to look at destiny numbers for two groups of presidents, I needed to look more closely at the data, so I created histograms of the proportions of presidents with each destiny number, for the two time periods. The histograms appear below. By looking at the histograms, we can see that, if we ignore the eight’s in the earlier time period and the two’s in the later time period, there is quite a shift to larger destiny numbers in the later time period.

I decided I would do hypotheses tests on the data using three methods, two nonparametric approaches and a parametric approach. The nonparametric tests were the Mann-Whitney-Wilcoxon test, also known as the rank sum test, and the randomization test. I also did a two sample z-test of comparison of means, which is a parametric test.
The Rank Sum Test
The rank sum test is described by Randles and Wolfe, in Introduction to the Theory of Nonparametric Statistics, published by Wiley, in 1979, on pages 39-45. For the rank sum test, the two data sets are merged and ranked and the ranks of one of the data sets are summed. Then, the expected value for the sum of the ranks, which is called ‘W’ for Wilcoxon, is n*(m +n+1)/2 and the variance is n*m*(n+m+1)/12, where n is the sample size of the sample whose ranks were summed and m is the sample size of the other sample. For our study, n equals 15 (for the first fifteen presidents) and m equals 28 (for the last 28 presidents). In our case, I did a one sided test that the statistic, W, calculated from the data, is less than what one would expect on average if the underlying distribution is the same for both time periods.
When one does a rank sum test, one makes two assumptions about the two underlying distributions. The first assumption is that the distributions are continuous, which implies that the probability of seeing ties in the ranks (a value showing up more than once in the data set) is zero. The second assumption is that the shapes of the two distributions are the same, with the only possible difference between the distributions being a shifting of one distribution to the left or right of the other. Neither assumption is true in our case.
In Snedecor and Cochran’s, Statistical Methods, 7th edition, published by Iowa State University Press, in 1980, on pages 144-145, Snedecor and Cochran describe a rank sum test. Snedecor and Cochran apply the test in comparing two data sets, with both data sets having discrete data with ties. Since Snedecor and Cochran work with discrete data with ties, I believe the continuity assumption is not necessarily critical. According to Snedecor and Cochran, we adjust for ties by setting the ranks of a tie equal to the same number, the mean of the ranks involved in the tie. (e.g., If the values of the the observations are 1, 1, 4, 8, 8, 8, then the ranks would be 1.5, 1.5, 3, 5, 5, 5, where 1.5 equals ( 1 + 2 ) / 2 and 5 equals ( 4 + 5 + 6 ) / 3. If the first, fifth, and sixth observations were the data set we were interested in, then W would equal ( 1.5 + 5 + 5 ) or 11.5).
Even though the data for the first 15 presidents is skewed right and the data for the last 28 presidents is skewed left, the basic shapes of the two distributions are similar,
so we will assume that the shape assumption is not too far off. Obviously, two distributions bounded by the same numbers cannot maintain the same shape if the location parameter shifts.
If the two data sets are small enough, the critical values for W are tabulated. If there are no ties, the free computer program, R, will give exact probabilities for W for data sets of any size. For data sets with ties, the computer program, R, does an asymptotic test, which can be done with or without a correction for continuity. Randles and Wolfe, on pages 352-353, describe exact methods to deal with the ties. For larger data sets, Snedecor and Cochran write that, if the two data sets come from the same distribution, then ( the absolute difference of W and ( n + m + 1 ) / 2 ) minus 0.5, all divided by ( the square root of n * m * ( n + m + 1 ) / 12 ), is distributed approximately normally with the mean equal to zero and the variance equal to one. Other authors do not subtract out the 0.5. I will call the Snedecor and Cochran result, ‘Zsc’, and the unadjusted statistic, ‘Zoa’.
Given the sizes of the data sets and given that there are ties, I used the asymptotically normal estimators. I also did the two tests in R. I am not sure what R does to find R’s estimates. The other two estimates are the areas under the standard normal curve to the left of Zsc and Zoa, respectively. In the table below, the values of W, the expected value of W, the variance of W, Zsc, Zoa and the p-values by the four methods are given. The four p-values do not agree, but the estimates are close. We can see that the rank sum test gives a 16% to 17% chance of seeing the ranks of the data in the order that we observed, or a more extreme order, if the actual underlying distributions for the earlier and later groups of presidents are the same.
| Results of the Rank Sum Test on the Presidential Data |
| W = 292, E(W) = 330, Var(W) = 1540 |
| Zsc = -0.9671, Zoa = -0.9683 |
| Version of Test |
p-value |
| Snedecor and Cochran |
0.1696 |
| Other Authors |
0.1664 |
| R – No Continuity Correction |
0.1641 |
| R – Continuity Correction |
0.1673 |
The Randomization Test
The second test is a randomization test, also called a permutation test. Phillip Good, in Permutation Tests, A Practical Guide to Resampling Methods for Testing Hypotheses, published by Springer, in 2000, provides a good description of the randomization test. A randomization test is based strictly on the data. No asymptotic results are applied. From the two data sets, a statistic is calculated. The two data sets are then merged. Then all of the permutations of the combined data sets are found and, for each permutation the value of the statistic is calculated. The value of the statistic calculated from the actual data sets is compared to the collection of the values found from all of the permutations of the data. If the statistic from the actual data sets is unusually large or small with respect to the collection of all of the possible values from the permutations, then we tend to believe that there is a difference in the processes generating the two data sets.
The statistic for our case is the difference between the mean of the destiny numbers for the first fifteen presidents and the mean of the destiny numbers for the last twenty-eight presidents. There are 43 factorial divided by the product of 15 factorial and 28 factorial permutations of the forty-three presidents destiny numbers divided into groups of fifteen and twenty-eight. That is about 152 billion permutations of the forty-three numbers. Below is a histogram of differences between the mean of the first fifteen numbers and the mean of the last twenty-eight numbers for 10,000 randomly generated permutations of the data. The arrow in the graph points to the actual observed difference.
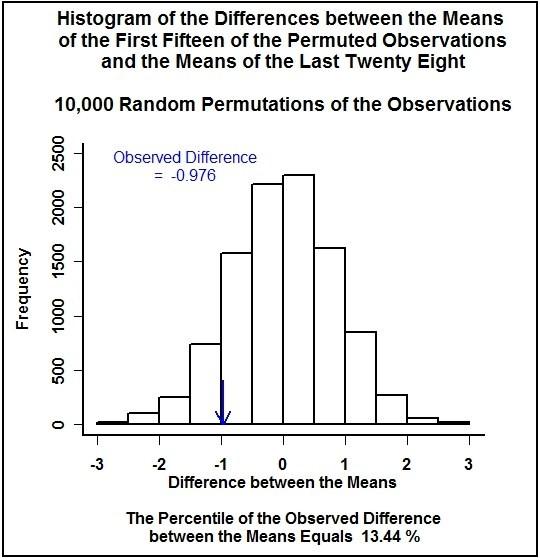
Obviously, calculating the statistic for 152 billion permutations is impractical (and unnecessary). The forty-three observations fall into only nine classes (the nine
destiny numbers), so a given pattern of the first fifteen numbers (which determines the pattern of the other twenty-eight numbers) will repeat over many permutations. Using R, I was able to determine that there are 149,139 unique patterns for the first fifteen numbers in the permutations.
The number 149,139 is far more tractable than 152 billion for computational purposes. However, we need to know how many permutations have each of the 149,135 patterns. The theory of multivariate hypergeometric distributions gives the number of permutations that have any given pattern out of the 149,139 possible patterns. (See Discrete Multivariate Analysis, Theory and Practice, by Bishop, Fienberg, and Holland, published by the MIT press, in 1975, pages 450-452, as one source for information about the multivariate hypergeometric distributions.)
To demonstrate how the number of permutations for a given pattern is calculated, of our forty-three presidents, 3 have a destiny number of one, 8 have two, 2 have three, 3 have four, 4 have five, 6 have six, 5 have seven, 8 have eight, and 4 have nine. One possible pattern of fifteen numbers out of the forty-three is 2 one’s, 5 two’s, 2 three’s, 1 four, 0 five’s, 5 sixes, 0 seven’s, 0 eight’s, and 0 nine’s. Then, looking just at the one’s (3 presidents in the full dataset and 2 in the example pattern), from Bishop, et.al., there are 3 choose 2 ( which equals ( 3 factorial ) divided by the quantity ( ( 2 factorial ) times ( ( 3 minus 2 ) factorial ) ) ), or 3, ways of choosing two of the three presidents with a destiny number of one. To explain a little further, the presidents with destiny number one are Washington, Taylor, and McKinley. The three possible ways of choosing two presidents with destiny number one are Washington and Taylor, Washington and McKinley, and Taylor and McKinley.
There are 8 choose 5, which equals 56, ways of choosing five presidents with the two destiny number; 2 choose 2, or 1 way, of choosing two presidents with destiny number three; 3 choose 1, or 3 ways, of choosing one president with the four destiny number; 4 choose 0, or 1 way, of choosing no presidents with destiny number five; 6 choose 5, or 6 ways, of choosing five presidents with a destiny number of six; and just one way of choosing no presidents with destiny number seven; one way for no presidents with destiny number eight; and one way for no presidents with destiny number nine.
Combining the ways of choosing the destiny numbers, there are ( 3 x 56 x 1 x 3 x 1 x 6 x 1 x 1 x 1 ), which equals 3024, permutations with the pattern ( 2 – 5 – 2 – 1 – 0 – 5 – 0 – 0 – 0 ) out of the pattern ( 3 – 8 – 2 – 3 – 4 – 6 – 5 – 8 – 4 ). Note again that the sum of the numbers 2, 5 , 2, 1, 0, 5, 0, 0, 0 equals 15, so the pattern is a pattern of fifteen out of the pattern of the forty-three actual presidents.
We are interested in the permutations for which the difference between the mean of the chosen fifteen destiny numbers and the mean of the other twenty-eight destiny numbers is less than or equal to the difference in the means found in the actual data. Algebraically, if the sum of the chosen fifteen destiny numbers is less than or equal
to the sum of the destiny numbers of the first fifteen presidents, then the difference in the means will be less than or equal to the difference in the actual data. For the presidents’ destiny numbers, the sum of the destiny numbers for the first fifteen presidents is 70, so we are interested in permutations for which the sum of the
chosen fifteen destiny numbers is less than or equal to 70.
To continue on with our pattern of fifteen given above, the sum of the destiny numbers in the pattern is ( 2 x 1 + 5 x 2 + 2 x 3 + 1 x 4 + 0 x 5 + 5 x 6 + 0 x 7 + 0 x 8 + 0 x 9 ), which equals 52. Since fifty-two is less than seventy, we would include the 3024 permutations with the pattern in our count of permutations for which the difference between the means of the two groups is less than the observed difference.
I used R to count the number of permutations with the sum of the chosen destiny numbers less than or equal to seventy. (The code I used can be found at R code.) Out of the possible 152 billion permutations, 13.69% had a destiny number sum less than or equal to seventy. So, for the randomization test, under assumptions discussed below, the p-value of the test is 0.1369, a bit smaller than the results of the rank sum tests.
| Results of the Randomization Test on the Presidential Data |
| Number of Permutations = 152 billion |
| p-Value = 0.1369 |
The z-test
If any test is the work horse of hypothesis testing, the z-test is a good candidate. Because of the central limit theorem, for a random sample from just about any distribution, as the size of the sample increases, the distribution of the mean of the sample approaches a normal distribution. The mean of the limiting normal distribution is the same as the mean of the underlying distribution and the variance of the limiting normal distribution is the variance of the underlying distribution divided by the sample size. (For one reference, see Introduction to Mathematical Statistics, Fourth Edition, by Hogg and Craig, published by Macmillan, in 1978, pages 192-195.)
The central limit theorem applies to a single sample mean. The z-test for our case involves comparing two sample means, rather than doing inference on a single sample mean. If the means that are being compared are asymptotically normal, then, in Testing Statistical Hypotheses, Second Edition, by Lehmann, published by Wiley, in 1986, on page 204, Lehmann give the result that the difference between two independent, asymptotically normal random variables is also asymptotically normal to a normal distribution with the mean equal to the underlying mean of the difference and variance equal to the underlying variance of the difference. So, under the assumption of random selection of presidents with regard to destiny numbers, we can apply the central limit theorem to the presidents’ data.
If, for the presidents’ destiny numbers, we start by assuming that each president is equally likely to have each destiny number and that the selections of the presidents (by ballot or by the death or resignation of the previous president) are independent with regard to destiny numbers, then, the underlying distribution of the destiny number for any president would be a discrete uniform distribution that takes on the values from one to nine with constant probability equal to one divided by nine. So, for each of the individual presidents, the mean of the underlying distribution of the president’s destiny number would be five and the variance would be sixty divided by nine. (See Hogg and Craig, pages 48-49.)
To make inference about the difference between the means, we calculate the z statistic by dividing the observed difference by the square root of the variance of the difference. Since the random trials are assumed to be independent, the variance of the difference is the sum of the variances of the two means. So, the variance of the difference of the observed means, under our assumptions of a discrete uniform distribution and random trials, is just sixty divided by nine times the sum of one divided by fifteen and one divided by twenty-eight. The test is given in the table below.
A z-test of the Difference Between the Means of the Destiny
Numbers for the Two Time Periods |
|
number |
mean |
standard error |
| Earlier Presidents |
15 |
4.6667 |
0.6666 |
| Later Presidents |
28 |
5.6429 |
0.4880 |
| Difference between the Means = -0.9762 |
Standard Error of the Difference = 0.8261 |
| z = -1.1816 |
p-value = 0.1187 |
Since we are using the central limit theorem, if two sample sizes are large enough, the difference between the sample means, divided by the square root of the variance of the difference, should be distributed close to normal with mean equal to zero and variance equal to one. The sample size of fifteen is a bit small for the central limit theorem to hold, since our data has two peaks (is bimodal) in each of the two time periods. However, we will calculate the p-value just to compare the result to the other p-values we have calculated. The p-value is the area under the standard normal curve to the left of the calculated z statistic. For the presidents’ destiny numbers, the p-value is 0.1187. The calculation of the z-statistic is shown in the table. So, for the z-test, we estimate that there is about a 12% chance of seeing a difference between the means of the destiny numbers for the two groups of presidents of the size observed or larger, if we assume random trials.
The Hypothesis Tests
Now that we have found p-values for the three methods of testing, we will state our assumptions, our hypotheses, and our conclusion.
For the rank sum test, we assume that the distribution of the destiny numbers is continuous and the distribution for the earlier presidents has the same shape as the
distribution for the later presidents. Neither assumption is met by our data. Under the null hypothesis, we assume that the two distributions are the same.
For the randomization test, we use the assumption that the observations are independent (or, at least, exchangeable), as discussed in the next section, in order to make use of the percentile of the observed difference. The test is based on the data, with no other assumptions, except that, under the null hypothesis, we assume that the underlying distribution is the same for both data sets.
For the z-test, we assume, under that null hypothesis, that the presidents’ destiny numbers are distributed uniformly and are the result of independent trials and that the sample sizes are large enough to apply the central limit theorem. The sample size of the first group of presidents is a bit small for applying the central limit theorem, given the bimodal nature of the data.
Rather than using the assumptions on which the three tests are based for three sets of hypotheses, I used a common set of hypotheses for the three tests. I chose the null hypothesis for all of the tests to be that the underlying mean destiny number for the earlier fifteen presidents is the same as the underlying mean destiny number of the later twenty-eight presidents. Our alternative hypothesis, for all of the tests, is that the underlying mean destiny number of the earlier fifteen presidents is less than the underlying mean destiny number of the later twenty-eight presidents.
Then, the assumption of equal means behind the null hypotheses is more general than the distributional assumptions behind any of the three tests. Being more general, if we would reject the null hypotheses for each of the three tests, then we would necessarily reject the assumption that the means are equal. I have chosen to use a significance level of 10%, since the sample size for the earlier presidents is small. However our p-values vary from 0.1187 to 0.1696, all larger than the alpha level of 0.10, so we conclude that we do not have enough evidence to reject the null hypothesis of equal underlying means. We think that there is somewhere between a 12% and 17% chance of seeing a difference between the means of the size observed or of a larger (more negative) size if the underlying distributions for the destiny numbers of the two presidential groups are the same, so a difference of the size observed would occur quite often.
Discussion
For the rank sum tests, our assumptions are not met, so we do not expect to get exact results for the p-values. I suspect that the rank sum tests are quite unstable compared to the z-test and the randomization test, based on the set of rank sum tests done above and another set of rank sum tests done below.
As mentioned above, Phillip Good provides a good discussion of the history of and the assumptions behind the randomization test. According to Good, if we assume that the observations are independent (or exchangeable), we just need the assumption, under the null hypothesis, that the data for the two time periods come from the same distribution for the test to be exact (i.e., for the expected value of the p-value associated with the test to be accurate under the null hypothesis). So, if the forty-three destiny numbers represent a random sample of destiny numbers from some underlying population of destiny numbers of persons that might become president, then the p-value (13.69%) is the estimate of the probability of the time we will see a difference of the size observed or of a more negative size.
The result of the z-test compared with the randomization test agrees with what we would expect, given the that we are using the central limit theorem on data that is not normal. I will demonstrate why we would expect the z-test to give a smaller p-value than the randomization test. We are assuming a uniform distribution for the nine possible values that the destiny numbers can equal. Since the data is uniform, the distribution of the mean of a sample from the data will be more triangular than the normal distribution. For a sample size of two, the distribution of the mean is exactly triangular and the distribution converges to the normal distribution as the sample size increases. Since the distribution of the sample mean for the uniform distribution is more triangular than the normal distribution, the height of the distribution in the tails will always be higher than the height of the normal curve, which means that the p-value for the actual distribution of the mean will be larger than what the normal curve would predict, if the z statistic is in the tail rather than the center of the distribution. In our case, the p-value for the randomization test is larger than the p-value for the z-test, as expected.
In the section Where to Start?, I made the statement that the population of interest is the population of native male citizens of this country since the country’s inception. Because I am a survey sampler, I tend to use the survey sampling approach to statistics. Under the survey sampling approach, the presidents would be a probability sample from the population, with the destiny number being a fixed number associated with each chosen president. Since the population of the country has increased dramatically over the years, and, since we only elect one president every four years, we cannot use the approach of the presidents being a random sample from the population of interest. Otherwise, we would have far more presidents from the later years than from the earlier years, which is an impossibility, given that presidents are somewhat evenly distributed over time.
On page 124, Hogg and Craig describe what constitutes a random sample from a distribution, using an approach more usual in statistics. A sample is considered random if, for the random variables measured, the random variables are mutually stochastically independent and the probability distribution functions of the random variables are all the same. So, one way out of the assumptional difficulty caused by the survey sampling approach is to assume that destiny numbers of the presidents are a random sample from an underlying distribution. Under the null hypothesis, we would assume that the destiny numbers are the result of random draws from a common underlying probability distribution that does not vary over time.
Are we justified in assuming that the destiny numbers of the presidents are the result of a random process, since becoming president does not involve a random process? The probabilistic results (the p-values) calculated above are based on the assumption that the observations are the result of a random process. My approach to this conundrum is to state the caveat that the results of the tests are the results that would apply if we knew the selection process were random. Certainly, if there is nothing to numerology and if there is not some artifact present in the birth demographics, one would have no reason to think that any president would be more likely to have a given destiny number than any other president. However, just picking out objects from a group of objects is not a random process.
I did the three types of tests out of curiosity. By the randomization test, we can say that the 13.69% chance of seeing the difference in the means of the size observed or more negative, if the underlying distributions for the two time periods are the same, is an unbiased estimate of the underlying probability under the null hypothesis. The assumptions for the test are that the chance of a president having a given destiny number is the same for all presidents and is not affected for any given president by any other president. We make no assumption as to what the distribution looks like.
A p-value greater than or equal to 13.69% happens quite often if the null hypothesis is true. Also, we looked at the data before deciding what to test, so we should be very conservative (e.g., look for a very small p-value) in our choice of significance level. Although the z and rank sum tests are only asymptotically exact (under the violations of the assumptions of each of the tests), the p-values for the z and rank sum tests agree quite well with the p-value for the randomization test.
Two’s and Eight’s
Stopping here would be good, but I am going to look a little closer at the data. In our observed data, the destiny numbers two and eight stand out. In the table below is a list of the proportions observed for the nine destiny numbers for the two time periods, and the average of the proportions for the two time periods. We can see that the destiny numbers two and eight occur about twice as often as the other numbers, when we average the proportions for the two time periods. Although I have not given the tests here, there is some reason to believe, on the basis of probability, that the distribution of the two’s and eight’s is different from the distribution of the other seven destiny numbers.
Observed Proportions for the Destiny Numbers of the Presidents
– for the Earlier and Later Time Periods and for the Average of
the Two Time Periods |
| Destiny Number |
Early Presidents |
Later Presidents |
Average |
| 1 |
0.13 |
0.04 |
0.08 |
| 2 |
0.20 |
0.18 |
0.19 |
| 3 |
0.13 |
0.00 |
0.07 |
| 4 |
0.07 |
0.07 |
0.07 |
| 5 |
0.07 |
0.11 |
0.09 |
| 6 |
0.07 |
0.18 |
0.12 |
| 7 |
0.00 |
0.18 |
0.09 |
| 8 |
0.27 |
0.14 |
0.20 |
| 9 |
0.07 |
0.11 |
0.09 |
| Total |
1.01 |
1.01 |
1.00 |
Perhaps there is something special about the numbers two and eight that causes presidents to be chosen with destiny numbers two and eight at a more constant rate, independent of time period. If we calculate p-values for the same tests that we did above, except excluding presidents with destiny numbers of two or eight, we get the results shown in the table below. We can see that the p-values are all smaller than 0.025. Doing the same hypothesis tests that we did above, except using a significance level of 0.025 and not including the presidents with destiny numbers two and eight, we reject the null hypothesis that the mean of the destiny numbers for the earlier presidents is the same as the mean of the destiny numbers for the later presidents. We accept the alternative hypothesis that the mean of the destiny numbers for the earlier time period is less than the mean for the later time period. I feel that using a level of 0.025 for the significance level for our hypotheses tests is okay, since the data sets which we are comparing are small, of size eight and nineteen. We use a conservative significance level since our hypothesis tests were based on looking at the data. Our tests and assumptions indicate that, if there is no difference between the underlying distribution of the destiny numbers for presidents who do not have a destiny number of two or eight, we estimate that we would see a difference of the size observed, or larger (more negative), less than two and one-half percent of the time.
p-Values for Tests of the Difference Between the Mean Destiny
Numbers for the Two Time Periods – for Presidents with Destiny
Number Not Equal to Two or Eight |
| Test |
p-value |
| Rank Sum – Snedecor and Cochran |
0.0168 |
| Rank Sum – Other Authors |
0.0158 |
| Rank Sum – R – No Continuity Correction |
0.0147 |
| Rank Sum – R – Continuity Correction |
0.0157 |
| Randomization |
0.0211 |
| z-Test |
0.0207 |
We note that the p-values for the rank sum tests are smaller than either the randomization test or the z-test, unlike the p-values for the rank sum tests found above in our first set of hypotheses tests. For the z-test, the p-value is smaller than the p-value for the randomization test, as we would expect. The randomization test remains exact under the assumption of presidents coming to power being random trials with regard to destiny numbers.
Conclusions
So, what do we conclude? I would say that, even though we fail reject the null hypothesis that earlier presidents were not more likely than later presidents to have smaller destiny numbers when we include all of the presidents, there does seem to be a difference if we do not include the presidents with two’s and eight’s for destiny numbers. To me, there appears to be a difference between the distributions for the two time periods. My hypotheses were not formed before I looked at the data. Instead, my hypotheses are based on the data, so the rejection of the null hypothesis for the second set of tests is suspect. In one approach to experimental work, when one observes an effect in a sample by doing exploratory analysis, one forms a set of hypotheses and takes another sample to test the hypotheses. We only have data for presidents who have served. We cannot take another sample. So, our results are suspect. As time goes by, we will have destiny numbers for future presidents and will see if the destiny numbers continue to stay high or be two’s or eight’s. We will, then, have hypotheses tests that will not be suspect. Also, we might research leaders in other countries, forming our hypotheses before looking at the leadership data, with the hypotheses based on our research here.
As to the numerology, perhaps persons with a higher destiny number are on a more complex path than those with a smaller destiny number. I do not know. I am just a student of numerology and have no training or extensive experience to make such
a conclusion. As far as the result of the research goes, I find the result interesting and suspend judgment as to what the result means.
Links
Some links to numerological sites are
http://www.astrology-numerology.com/numerology.htm
http://en.wikipedia.org/wiki/Numerology
http://www.cafeastrology.com/numerology.html#one .
These three sites give quite a bit of information about numerology, particularly the first one. At Michael McClain’s site, the destiny number is called the life path number. At the Cafe Astrology site, the destiny number is called the birth path number. A quick search on the web would give many other places to find numerological information.
Wikipedia provides basic information about the tests done here. Some links are
Rank Sum Test
Randomization Test
One Sample Location z Test and Two Sample Location t Test.